Publications
2026
- Grounding Machine Creativity in Game Design Knowledge Representations: Empirical Probing of LLM-Based Executable Synthesis of Goal Playable Patterns under Structural ConstraintsHugh Xuechen Liu , and Kıvanç TatararXiv preprint arXiv:2603.07101, 2026
- Expanding the machine: Notating generative synthesis with a state-based representation and a navigable timbre spaceVincenzo Madaghiele , Leonard Lund , Derek Holzer , and 3 more authorsOrganised Sound, Jan 2026
Notating electroacoustic music can be challenging due to the uniqueness of the instruments employed. Electronic instruments can include generative components that can manipulate sound at different time levels, in which parameter variations can correlate non-linearly to changes in the instrument’s timbre. The way compositions for electronic instruments are notated depends on their interfaces and the parameter controls available to performers, which determine the state of their sound-generating system. In this article, we propose a notation system for generative synthesis based on a projection from its parameter space to a timbre space, allowing to organise synthesiser states based on their timbral characteristics. To investigate this approach, we introduce the Meta-Benjolin, a state-based notation system for chaotic sound synthesis employing a three-dimensional, navigable timbre space and a composition timeline. The Meta-Benjolin was developed as a control structure for the Benjolin, a chaotic synthesiser. Framing chaotic synthesis as a specific instance of generative synthesis, we discuss the advantages and drawbacks of the state- and timbre-based representation we designed based on the thematic analysis of an interview study with 19 musicians, who composed a piece using the Meta-Benjolin notational interface.
@article{madaghiele_expanding_2026, title = {Expanding the machine: Notating generative synthesis with a state-based representation and a navigable timbre space}, issn = {1355-7718, 1469-8153}, shorttitle = {Expanding the machine}, doi = {10.1017/S1355771825100915}, language = {en}, urldate = {2026-01-30}, journal = {Organised Sound}, author = {Madaghiele, Vincenzo and Lund, Leonard and Holzer, Derek and Kelkar, Tejaswinee and Tatar, Kıvanç and Holzapfel, Andre}, month = jan, year = {2026}, pages = {1--12}, }
2025
- AEGIS: Authentic Edge Growth In Sparsity for Link Prediction in Edge-Sparse Bipartite Knowledge GraphsHugh Xuechen Liu , and Kıvanç TatarJan 2025
Bipartite knowledge graphs in niche domains are typically data-poor and edge-sparse, which hinders link prediction. We introduce AEGIS (Authentic Edge Growth In Sparsity), an edge-only augmentation framework that resamples existing training edges -either uniformly simple or with inverse-degree bias degree-aware -thereby preserving the original node set and sidestepping fabricated endpoints. To probe authenticity across regimes, we consider naturally sparse graphs (game design pattern’s game-pattern network) and induce sparsity in denser benchmarks (Amazon, MovieLens) via high-rate bond percolation. We evaluate augmentations on two complementary metrics: AUC-ROC (higher is better) and the Brier score (lower is better), using two-tailed paired t-tests against sparse baselines. On Amazon and MovieLens, copy-based AEGIS variants match the baseline while the semantic KNN augmentation is the only method that restores AUC and calibration; random and synthetic edges remain detrimental. On the text-rich GDP graph, semantic KNN achieves the largest AUC improvement and Brier score reduction, and simple also lowers the Brier score relative to the sparse control. These findings position authenticity-constrained resampling as a data-efficient strategy for sparse bipartite link prediction, with semantic augmentation providing an additional boost when informative node descriptions are available.
@article{liu2025aegisauthenticedgegrowth, title = {AEGIS: Authentic Edge Growth In Sparsity for Link Prediction in Edge-Sparse Bipartite Knowledge Graphs}, author = {Liu, Hugh Xuechen and Tatar, Kıvanç}, year = {2025}, eprint = {2509.22017}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, } - Neural audio instruments: epistemological and phenomenological perspectives on musical embodiment of deep learningVictor Zappi , and Kıvanç TatarFrontiers in Computer Science, Aug 2025Publisher: Frontiers
Neural Audio is a category of deep learning pipelines which output audio signals directly, in real-time scenarios of action-sound interactions. In this work, we examine how neural audio-based artificial intelligence, when embedded in digital musical instruments (DMIs), shapes embodied musical interaction. While DMIs have long struggled to match the physical immediacy of acoustic instruments, neural audio methods can magnify this challenge, requiring data collection, model training and deep theoretical knowledge that appear to push musicians toward symbolic or conceptual modes of engagement. Paradoxically, these same methods can also foster more embodied practices, by introducing opaque yet expressive behaviors that free performers from rigid technical models and encourage discovery through tactile, real-time experimentation. Drawing on established perspectives in DMI embodiment literature, as well as emerging neural-audio-focused efforts within the community, we highlight two seemingly conflicting aspects of these instruments: on one side, they inherit many “disembodying” traits known from DMIs; on the other, they open pathways reminiscent of acoustic phenomenology and soma, potentially restoring the close physical interplay often missed in digital performance.
@article{zappi_neural_2025, title = {Neural audio instruments: epistemological and phenomenological perspectives on musical embodiment of deep learning}, volume = {7}, issn = {2624-9898}, shorttitle = {Neural audio instruments}, doi = {10.3389/fcomp.2025.1575168}, journal = {Frontiers in Computer Science}, author = {Zappi, Victor and Tatar, Kıvanç}, month = aug, year = {2025}, note = {Publisher: Frontiers}, keywords = {deep learning, artificial intelligence, embodied interaction, digital musical instruments, latent space, music performance, neural audio, neural audio instruments}, } - Imploding between the facts and concerns: analysing human–AI musical interactionKelsey Cotton , Anna-Kaisa Kaila , Petra Jääskeläinen , and 2 more authorsHumanities and Social Sciences Communications, Jun 2025Publisher: Palgrave
The advancement of AI-tools for musical performance has inspired exciting opportunities for interaction with musical-AI-agents. Interactions between humans and AI-agents in musical settings entail dynamic exchanges of control and power, and framings of AI-agents’ roles by human performers. We probe these framings and power-control exchanges through qualitative thematic lenses, drawing from post-phenomenology, matters of fact and concern and feminist science and technology studies. We contribute with a novel interdisciplinary analytical method as a tool for developers and designers of AI systems to help visibilise and examine the implicit, the wider connections and entangled filaments in Human–AI musical interactions.
@article{cotton_imploding_2025, title = {Imploding between the facts and concerns: analysing human–{AI} musical interaction}, volume = {12}, copyright = {2025 The Author(s)}, issn = {2662-9992}, shorttitle = {Imploding between the facts and concerns}, url = {https://www.nature.com/articles/s41599-025-04533-4}, doi = {10.1057/s41599-025-04533-4}, number = {1}, journal = {Humanities and Social Sciences Communications}, author = {Cotton, Kelsey and Kaila, Anna-Kaisa and Jääskeläinen, Petra and Holzapfel, André and Tatar, Kıvanç}, month = jun, year = {2025}, note = {Publisher: Palgrave}, keywords = {Science, technology and society, Cultural and media studies, Theatre and performance studies}, pages = {1--20}, }
2024
- A Deep Learning Framework for Musical Acoustics SimulationsJiafeng Chen , Kıvanç Tatar , and Victor ZappiIn AIMC 2024 , Aug 2024
The acoustic modeling of musical instruments is a heavy computational process, often bound to the solution of complex systems of partial differential equations (PDEs). Numerical models can achieve a high level of accuracy, but they may take up to several hours to complete a full simulation, especially in the case of intricate musical mechanisms. The application of deep learning, and in particular of neural operators that learn mappings between function spaces, has the potential to revolutionize how acoustics PDEs are solved and noticeably speed up musical simulations. However, extensive research is necessary to understand the applicability of such operators in musical acoustics; this requires large datasets, capable of exemplifying the relationship between input parameters (excitation) and output solutions (acoustic wave propagation) per each target musical instrument/configuration. With this work, we present an open-access, open-source framework designed for the generation of numerical musical acoustics datasets and for the training/benchmarking of acoustics neural operators. We first describe the overall structure of the framework and the proposed data generation workflow. Then, we detail the first numerical models that were ported to the framework. This work is a first step towards the gathering of a research community that focuses on deep learning applied to musical acoustics, and shares workflows and benchmarking tools.
@inproceedings{chen_sounding_2024, title = {A Deep Learning Framework for Musical Acoustics Simulations}, language = {en}, booktitle = {AIMC 2024}, author = {Chen, Jiafeng and Tatar, Kıvanç and Zappi, Victor}, month = aug, year = {2024}, url = {https://aimc2024.pubpub.org/pub/5cl1cvmy/release/1}, } - Sounding out extra-normal AI voice: Non-normative musical engagements with normative AI voice and speech technologiesKelsey Cotton , and Kıvanç TatarIn AIMC 2024 , Aug 2024
How do we challenge the norms of AI voice technologies? What would be a non-normative approach in finding novel artistic possibilities of speech synthesis and text-to-speech with Deep Learning? This paper delves into SpeechBrain, OpenAI and CoquiTTS voice and speech models with the perspective of an experimental vocal practitioner. Exploratory Research-through-Design guided an engagement with pre-trained speech synthesis models to reveal their musical affordances in an experimental vocal practice. We recorded this engagement with voice and speech Deep Learning technologies using auto-ethnography, a novel and recent methodology in Human-Computer Interaction. Our position in this paper actively subverts the normative function of these models, provoking nonsensical AI-mediation of human vocality. Emerging from a sense-making process of poetic AI nonsense, we uncover the generative potential of non-normative usage of normative speech recognition and synthesis models. We contribute with insights about the affordances of Research-through-Design to inform artistic working processes with AI models; how AI-mediations reform understandings of human vocality; and artistic perspectives and practice as knowledge-creation mechanisms for working with technology.
- Singing for the Missing: Bringing the Body Back to AI Voice and Speech TechnologiesKelsey Cotton , Katja Vries , and Kıvanç TatarIn Proceedings of the 9th International Conference on Movement and Computing , Utrecht, Netherlands, May 2024
Technological advancements in deep learning for speech and voice have contributed to a recent expansion in applications for voice cloning, synthesis and generation. Invisibilised stakeholders in this expansion are numerous absent bodies, whose voices and voice data have been integral to the development and refinement of these speech technologies. This position paper probes current working practices for voice and speech in machine learning and AI, in which the bodies of voices are “invisibilised". We examine the facts and concerns about the voice-Body in applications of AI-voice technology. We do this through probing the wider connections between voice data and Schaefferian listening; speculating on the consequences of missing Bodies in AI-Voice; and by examining how vocalists and artists working with synthetic Bodies and AI-voices are ‘bringing the Body back’ in their own practices. We contribute with a series of considerations for how practitioners and researchers may help to ‘bring the Body back’ into AI-voice technologies.
@inproceedings{cotton_singing_2024, language = {en}, author = {Cotton, Kelsey and de Vries, Katja and Tatar, Kıvanç}, month = may, title = {Singing for the Missing: Bringing the Body Back to AI Voice and Speech Technologies}, year = {2024}, isbn = {9798400709944}, publisher = {Association for Computing Machinery (ACM)}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3658852.3659065}, doi = {10.1145/3658852.3659065}, booktitle = {Proceedings of the 9th International Conference on Movement and Computing}, articleno = {2}, numpages = {12}, keywords = {AI, STS, artificial intelligence, body, musical AI, voice}, location = {Utrecht, Netherlands}, series = {MOCO '24} } - Interfacing ErgoJr with Creative Coding PlatformsMatteo Caravati , and Kıvanç TatarIn Proceedings of the 9th International Conference on Movement and Computing , Utrecht, Netherlands, May 2024
This paper introduces a project enabling non-coders to control a Poppy Ergo Jr. robotic arm with Dynamixel servomotors. Originally using a Raspberry Pi and Pixl board, various constraints related to importation led to adopting a ROBOTIS OpenCM9.04 board. A client-server architecture was implemented for remote control, with creative coding platforms (p5.js, Processing, Pure Data, Python) as clients. The server, utilizing a two-layer architecture, manages communication and interfaces with the ROBOTIS OpenCM9.04 board. The OSC and WebSocket protocols were chosen for communication due to their flexibility and their ease of use. Clients were developed for each platform, leveraging compatibility layers.
- A Shift in Artistic Practices through Artificial IntelligenceKıvanç Tatar , Petter Ericson , Kelsey Cotton , and 6 more authorsLeonardo, Apr 2024
The explosion of content generated by artificial intelligence (AI) models has initiated a cultural shift in arts, music, and media, whereby roles are changing, values are shifting, and conventions are challenged. The vast, readily available dataset of the Internet has created an environment for AI models to be trained on any content on the Web. With AI models shared openly and used by many globally, how does this new paradigm shift challenge the status quo in artistic practices? What kind of changes will AI technology bring to music, arts, and new media?
@article{tatar_shift_2024, title = {A Shift in Artistic Practices through Artificial Intelligence}, issn = {0024-094X}, url = {https://doi.org/10.1162/leon_a_02523}, doi = {10.1162/leon_a_02523}, urldate = {2024-04-09}, journal = {Leonardo}, publisher = {MIT Press}, author = {Tatar, Kıvanç and Ericson, Petter and Cotton, Kelsey and Del Prado, Paola Torres Núñez and Batlle-Roca, Roser and Cabrero-Daniel, Beatriz and Ljungblad, Sara and Diapoulis, Georgios and Hussain, Jabbar}, month = apr, year = {2024}, pages = {293--297}, }
2023
-
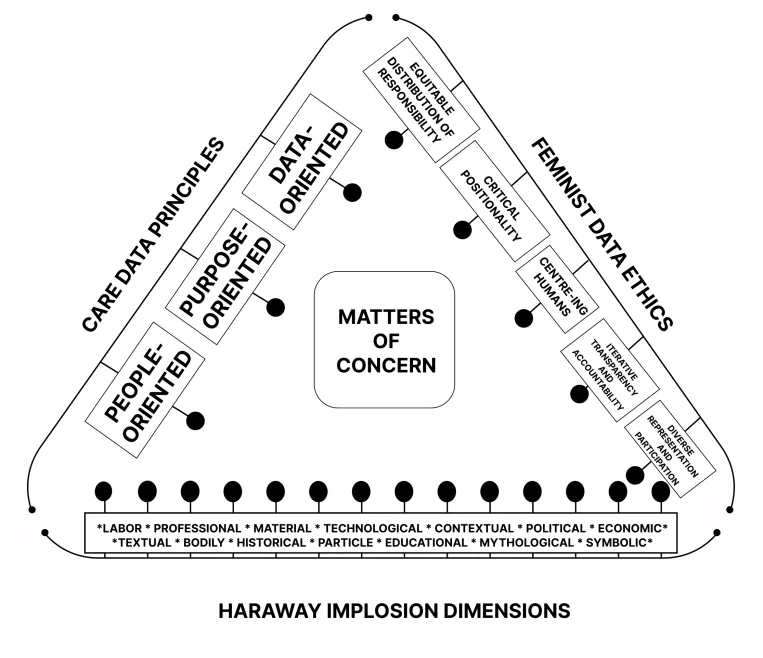 Caring Trouble and Musical AI: Considerations towards a Feminist Musical AIKelsey Cotton , and Kıvanç TatarIn AIMC 2023 , Aug 2023
Caring Trouble and Musical AI: Considerations towards a Feminist Musical AIKelsey Cotton , and Kıvanç TatarIn AIMC 2023 , Aug 2023The ethics of AI as both material and medium for interaction remains in murky waters within the context of musical and artistic practice. The interdisciplinarity of the field is revealing matters of concern and care, which necessitate interdisciplinary methodologies for evaluation to trouble and critique the inheritance of ‘residue-laden’ AI-tools in musical applications. Seeking to unsettle these murky waters, this paper critically examines the example of Holly+, a deep neural network that generates raw audio in the likeness of its creator Holly Herndon. Drawing from theoretical concerns and considerations from speculative feminism and care ethics, we care-fully trouble the structures, frameworks and assumptions that oscillate within and around Holly+. We contribute with several considerations and contemplate future directions for integrating speculative feminism and care into musical-AI agent and system design, derived from our critical feminist examination.
-
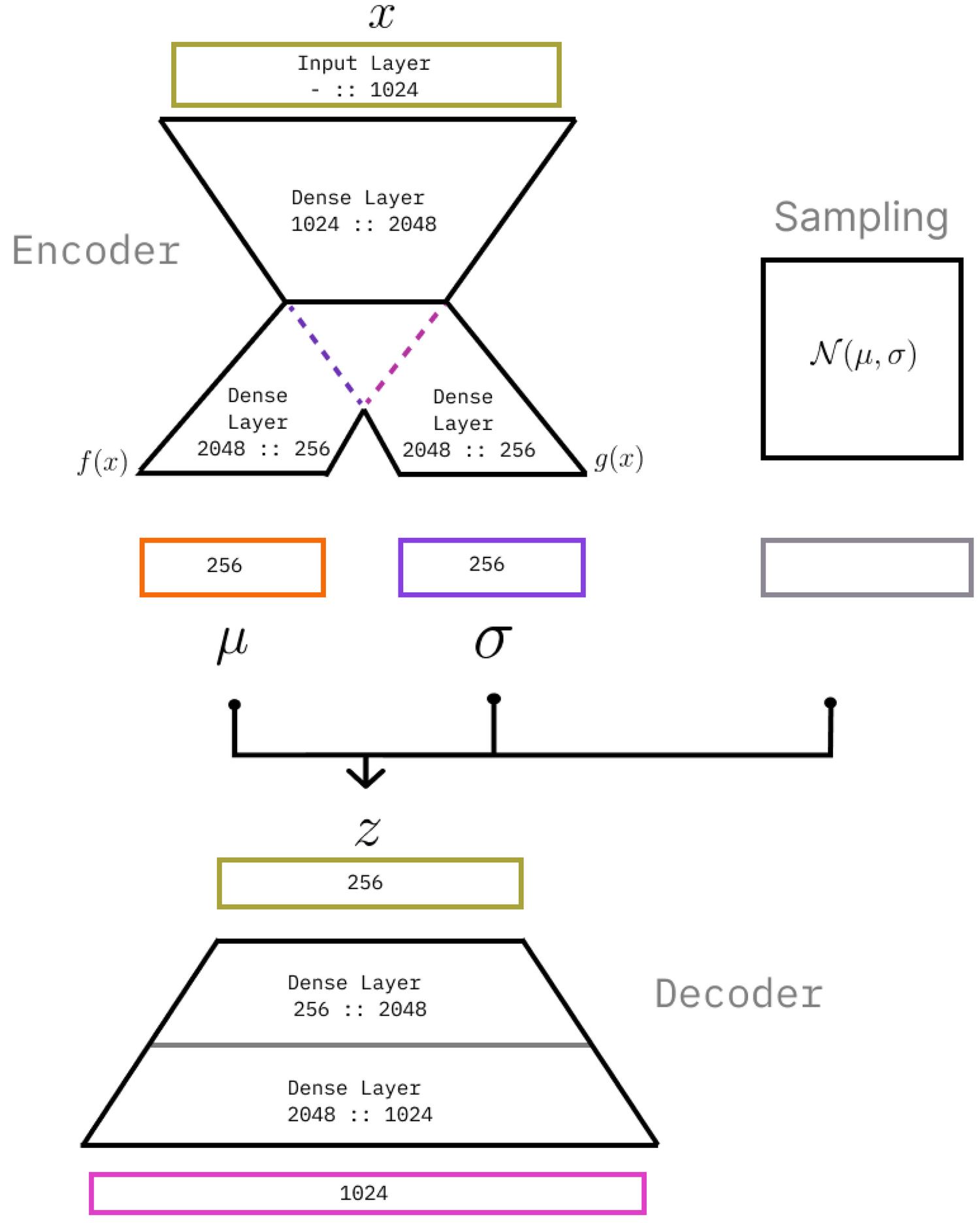 Sound Design Strategies for Latent Audio Space Explorations Using Deep Learning ArchitecturesKıvanç Tatar , Kelsey Cotton , and Daniel BisigIn Proceedings of Sound and Music Computing 2023 , Aug 2023
Sound Design Strategies for Latent Audio Space Explorations Using Deep Learning ArchitecturesKıvanç Tatar , Kelsey Cotton , and Daniel BisigIn Proceedings of Sound and Music Computing 2023 , Aug 2023The research in Deep Learning applications in sound and music computing have gathered an interest in the recent years; however, there is still a missing link between these new technologies and on how they can be incorporated into real-world artistic practices. In this work, we explore a well-known Deep Learning architecture called Variational Autoencoders (VAEs). These architectures have been used in many areas for generating latent spaces where data points are organized so that similar data points locate closer to each other. Previously, VAEs have been used for generating latent timbre spaces or latent spaces of symbolic music excepts. Applying VAE to audio features of timbre requires a vocoder to transform the timbre generated by the network to an audio signal, which is computationally expensive. In this work, we apply VAEs to raw audio data directly while bypassing audio feature extraction. This approach allows the practitioners to use any audio recording while giving flexibility and control over the aesthetics through dataset curation. The lower computation time in audio signal generation allows the raw audio approach to be incorporated into real-time applications. In this work, we propose three strategies to explore latent spaces of audio and timbre for sound design applications. By doing so, our aim is to initiate a conversation on artistic approaches and strategies to utilize latent audio spaces in sound and music practices.
@inproceedings{tatar_sound_2023, title = {Sound {Design} {Strategies} for {Latent} {Audio} {Space} {Explorations} {Using} {Deep} {Learning} {Architectures}}, language = {en}, author = {Tatar, Kıvanç and Cotton, Kelsey and Bisig, Daniel}, year = {2023}, booktitle = {Proceedings of Sound and Music Computing 2023}, } - On the importance of AI research beyond disciplinesVirginia Dignum , Donal Casey , Teresa Cerratto-Pargman , and 17 more authorsFeb 2023arXiv:2302.06655 [cs]
As the impact of AI on various scientific fields is increasing, it is crucial to embrace interdisciplinary knowledge to understand the impact of technology on society. The goal is to foster a research environment beyond disciplines that values diversity and creates, critiques and develops new conceptual and theoretical frameworks. Even though research beyond disciplines is essential for understanding complex societal issues and creating positive impact it is notoriously difficult to evaluate and is often not recognized by current academic career progression. The motivation for this paper is to engage in broad discussion across disciplines and identify guiding principles fir AI research beyond disciplines in a structured and inclusive way, revealing new perspectives and contributing to societal and human wellbeing and sustainability.
@misc{dignum_importance_2023, title = {On the importance of {AI} research beyond disciplines}, url = {http://arxiv.org/abs/2302.06655}, doi = {10.48550/arXiv.2302.06655}, urldate = {2023-03-03}, publisher = {arXiv}, author = {Dignum, Virginia and Casey, Donal and Cerratto-Pargman, Teresa and Dignum, Frank and Fantasia, Valentina and Formark, Bodil and Hammarfelt, Björn and Holmberg, Gunnar and Holzapfel, André and Larsson, Stefan and Lagerkvist, Amanda and Lakemond, Nicolette and Lindgren, Helena and Lorig, Fabian and Marusic, Ana and Rahm, Lina and Razmetaeva, Yulia and Sikström, Sverker and Tatar, Kıvanç and Tucker, Jason}, month = feb, year = {2023}, note = {arXiv:2302.06655 [cs]}, keywords = {Computer Science - Computers and Society}, }


2021
-
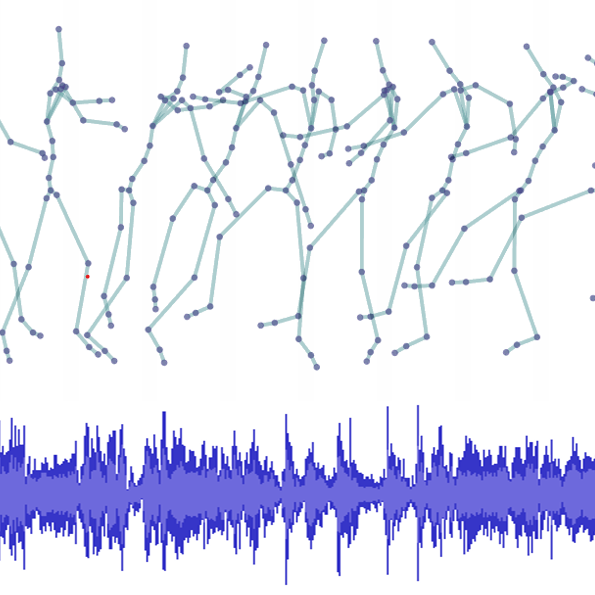 Raw Music from Free Movements: Early Experiments in Using Machine Learning to Create Raw Audio from Dance MovementsDaniel Bisig , and Kıvanç TatarIn Proceedings of the 2nd AI Music Creativity Conference (AIMC 2021) , Feb 2021
Raw Music from Free Movements: Early Experiments in Using Machine Learning to Create Raw Audio from Dance MovementsDaniel Bisig , and Kıvanç TatarIn Proceedings of the 2nd AI Music Creativity Conference (AIMC 2021) , Feb 2021Raw Music from Free Movements is a deep learning architecture that translates pose sequences into audio waveforms. The architecture combines a sequence-to-sequence model generating audio encodings and an adversarial autoencoder that generates raw audio from audio encodings. Experiments have been conducted with two datasets: a dancer improvising freely to a given music, and music created through simple movement sonification. The paper presents preliminary results. These will hopefully lead closer towards a model which can learn from the creative decisions a dancer makes when translating music into movement and then follow these decisions reversely for the purpose of generating music from movement.
@inproceedings{bisig_raw_2021, title = {Raw Music from Free Movements: Early Experiments in Using Machine Learning to Create Raw Audio from Dance Movements}, language = {en}, booktitle = {Proceedings of the 2nd AI Music Creativity Conference (AIMC 2021)}, author = {Bisig, Daniel and Tatar, Kıvanç}, year = {2021}, pages = {11}, }

2020
- Latent Timbre SynthesisKıvanç Tatar , Daniel Bisig , and Philippe PasquierNeural Computing and Applications, Oct 2020
We present the Latent Timbre Synthesis, a new audio synthesis method using deep learning. The synthesis method allows composers and sound designers to interpolate and extrapolate between the timbre of multiple sounds using the latent space of audio frames. We provide the details of two Variational Autoencoder architectures for the Latent Timbre Synthesis and compare their advantages and drawbacks. The implementation includes a fully working application with a graphical user interface, called interpolate_two, which enables practitioners to generate timbres between two audio excerpts of their selection using interpolation and extrapolation in the latent space of audio frames. Our implementation is open source, and we aim to improve the accessibility of this technology by providing a guide for users with any technical background. Our study includes a qualitative analysis where nine composers evaluated the Latent Timbre Synthesis and the interpolate_two application within their practices.
@article{tatar_latent_2020, title = {Latent {Timbre} {Synthesis}}, issn = {1433-3058}, url = {https://doi.org/10.1007/s00521-020-05424-2}, doi = {10.1007/s00521-020-05424-2}, language = {en}, urldate = {2020-11-09}, journal = {Neural Computing and Applications}, publisher = {Springer}, author = {Tatar, Kıvanç and Bisig, Daniel and Pasquier, Philippe}, month = oct, year = {2020}, }